NLP05. 워드 임베딩
NLP05. 워드 임베딩
01. 벡터화
02. 벡터화 실습 : 원-핫 인코딩 구현해보기
03. 워드 임베딩
04. Word2Vec
(1) 분포 가설
(2) CBoW
(3) Skip-gram과 Negative Sampling
(4) 영어 Word2Vec 실습과 OOV문제
05. 임베딩 벡터의 시각화
06. FastText
07. GloVe
=============================
01. 벡터화
[0] 용어 정리 및 준비사항
- 벡터화(vectorization) : 기계가 자연어 처리를 원활히 수행할 수 있도록 전처리 과정에서 텍스트를 벡터로 변환하는 과정
- BoW(Bag of Words) : 단어의 순서는 고려하지 않고, 단어의 등장 빈도만 고려해서 단어를 벡터화하는 방법. 내림차순 인덱스 부여
- OOV(Out Of Vocabulary) : 단어장에 없는 단어에 대처할 수 없어 난감한 문제
- DTM(문서 단어 행렬, Document-Term Matrix) : BoW를 사용하여 문서를 행으로, 단어를 열로 구성한 행렬. 문서 간 유사도를 비교하는 데 사용됨. 단어의 등장 빈도 반영됨
- 희소벡터(sparse vector) : BoW 또는 DTM과 같이 고차원 행렬에서 대부분의 값이 0인 벡터. 메모리 과다 사용 및 연산량 급증의 문제 야기함.
- 단어장(vocabulary) : DTM에서 중복을 배제한 단어들의 집합(set), 크기 V
- TF-IDF(Term Frequency- Inverse Document Frequency) : 모든 문서에 등장하는 단어는 중요도가 떨어지고, 특정 문서에 특정 단어가 빈번히 등장하면 중요도가 높은 단어임.
- One-hot encoding :
[2] Bag of Words/ DTM(Document Term Matrix)
[3] TF-IDF
[4] 원-핫 인코딩(one-hot encoding)
① 텍스트 데이터에서 단어장 작성
② 단어장의 단어들 고유 정수(인덱스) 부여(인덱스 부여 순서는 등장빈도의 내림차순)
③ 각 단어는 해당 인덱스 위치만 1이고 나머지는 0인 벡터 생성(one-hot vector, unit vector)
02. 벡터화 실습 : 원-핫 인코딩 구현해보기
[1] 벡터화 실습 프로세스
(Step1) 패키지 설치
(Step2) 전처리 이야기
(Step3) 토큰화 이야기
(Step4) 단어자 만들기
(Step5) 원-핫 벡터 만들기
[2] 케라스를 통한 원-핫 인코딩(one-hot encoding)
03. 워드 임베딩
[1] 희소 벡터의 문제점 :
(1) 자원의 저주(cusrse of dimensionality)
(2) 벡터 간 유사도 없음(내적이 0, orthogonal=독립적)
(3) 문제점 해결을 위한 제안
- 희소벡터인 원-핫 벡터의 문제 해결을 위해
단어장 크기 보다 작은 차원의 밀집 벡터를 학습 => 워드 임베딩
- 임베딩 벡터(embedding vector) : 워드 임베딩를 위한 실수값을 가진 밀집벡터(dense vector)
[2] 워드 임베딩(Word Embedding)
※ 원핫 벡터 vs 임베딩 벡터
| 구분 | 원-핫 벡터 | 임베딩 벡터 |
| 차원 | 고차원(단어장의 크기) | 저차원 |
| 다른 표현 | 희소 벡터의 일종 | 밀집 벡터의 일종 |
| 표현 방법 | 수동 | 훈련데이터로부터 학습함 |
| 값의 타입 | 1과 0 | 실수 |
| 기반 이론 | 빈도 기반 | 분포가설/학습 |
| 알고리즘 | 인덱스부여, 원-핫 인코딩 함수 적용 | keras.Embedding, Word2Vec, GloVe, LSA, FastText |
04. Word2Vec
(1) 배경 지식
[1] 분포 가설
- 언어학자 존 루퍼트 퍼스(John Rupert Firth)
You shall know a word by the company it keeps
(곁에 오는 단어들을 보면 그 단어를 알 수 있다)
- 분포 가설 : 비슷한 문맥에서 같이 등장하는 경향이 있는 단어들은 비슷한 의미를 가진다.
[2] Word2Vec 종류
- CBoW : 주변 단어를 통해 중심 단어 예측
- Skip-gram : 중심 단어를 통해 주변단어 예측
(2) CBoW(Continuous Bag of Words)
[1] 주요 용어
- 중심단어 center word : 예측해야 할 단어
- 주변단어(context word) : 예측에 사용되는 단어
- 윈도우(window) : 중심단어를 예측하기 위해 앞/뒤로 사용될 주변단어 수m. 총 2m의 단어
- 슬라이딩 윈도우 : 윈도우를 계속 움직여 주변단어와 중심단어를 바꿔가며 학습을 위한 뎅터 셋을 만드는 과정

- 룩업테이블(lookup table) : 원-핫 벡터와 가중치 행렬과의 곱은 가중치 행렬의 i위치에 있는 행을 그대로 가져오는 것과 동일함.
- 투사층(projection layer) : Word2Vect에서의 은닉층을 기존 신경망의 은닉층과 구분하기 위한 명칭. 기존 신경망의 은닉층과 달리 활성화 함수가 존재하지 않고 단순히 가중행렬과의 곱셈만 수행하기 때문임.
- 비지도학습(unsupervised learning) : 중심 단어와 주변단어로 feature변수와 label변수를 직접 만들어 학습을 함.
- 셸로우 러닝(shallow learning) : 딥러닝은 여러 은닉층을 가지고 학습을 하는 반면, 셸로우 러닝은 1개 은닉층을 포함한 3개 층으로 구성하여 학습을 진행함.
[2] 데이터 셋 : 윈도우 슬라이딩, (주변단어, 중심단어, 주변단어)
[3] CBoW 작동 메커니즘
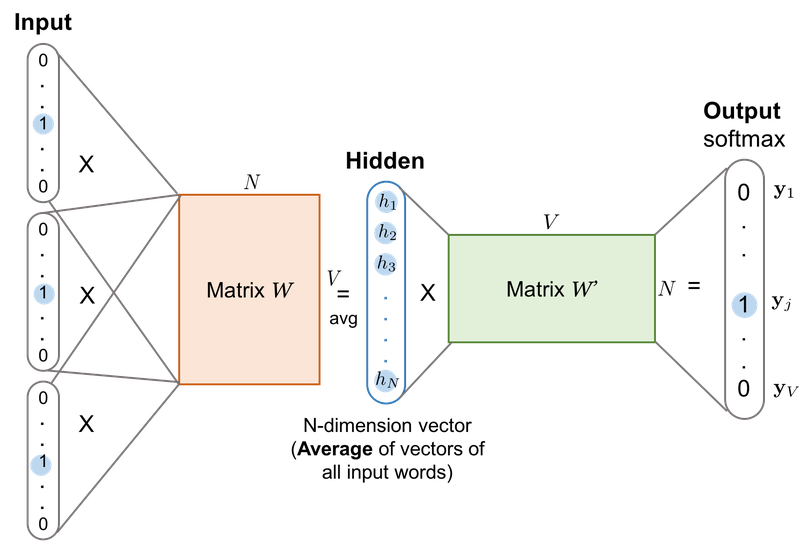
- V : 단어장(Vocabulary)의 크기
- N : 은닉층 노드 수(하이퍼파라미터)
[4] 은닉층 연산

[5] 은닉층에서 출력층으로 가는 과정과 출력층의 연산
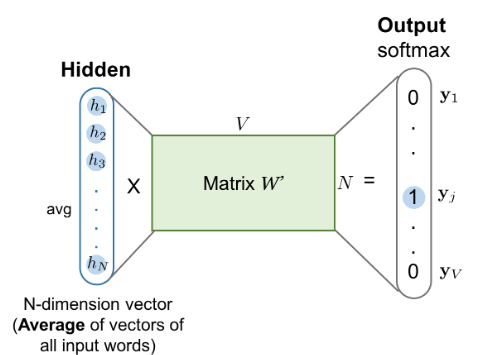
- 출력층 활성화 함수 : 소프트맥스 함수
- loss함수 : cross entropy
- 학습방향 : 출력층의 벡터를 중심 단어의 원-핫 벡터와의 손실을 최소화하도록 학습
- 임베딩 벡터(선택) : ①W의 행벡터 또는 ②W'의 열벡터 또는 ③W와 W'의 평균치
= Wor2Vec representation vector
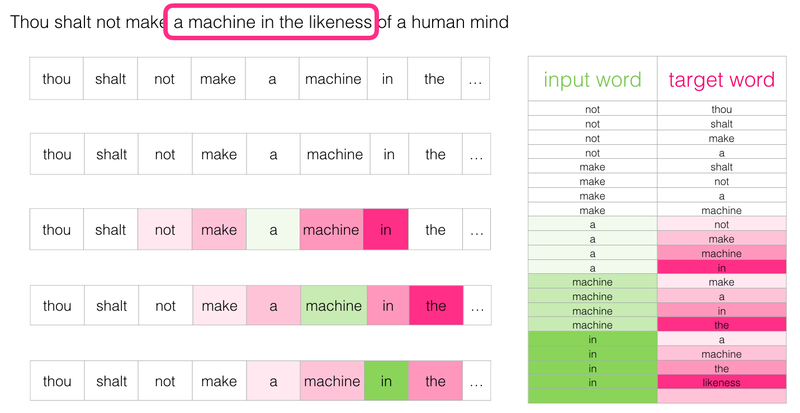
(3) Skip-gram과 Negative Sampling
[1] Skip-gram
(1) 데이터셋 (중심 단어, 주변 단어)
(2) 작동 메커니즘 : 학습 후 가중치 행렬 W의 행 또는 W'의 열로부터 임베딩 벡터 산출
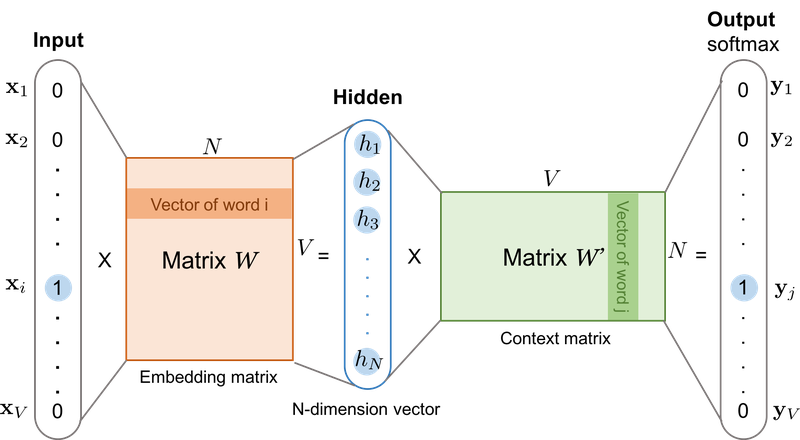
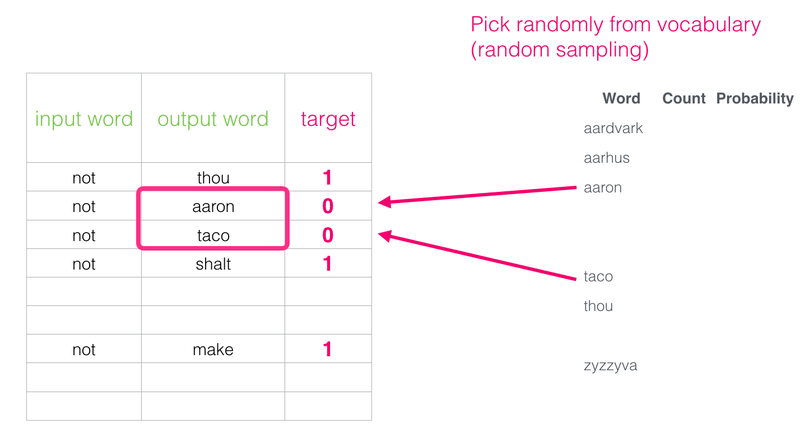
[2] 네거티브 샘플링(Negative Sampling)
- 연산량을 줄이기 위해서 다중 분류 문제(소프트맥스 함수)를 이진 분류 문제(시그모이드 함수)로 바꿈
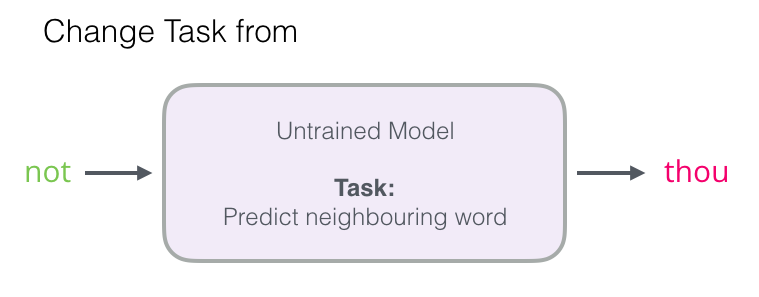


- 무작위로 단어장에 있는 아무 단어를 가져와 target word로 하는 '거짓 데이터셋'을 만들고 0으로 레이블링 해준다.
- 거짓 데이터셋을 만들기 때문에 이 방법을 negative sampling이라고 한다.

(4) 영어 Word2Vec 실습과 OOV문제
[1] 영어 Word2Vec 실습
[2] Word2Vec의 OOV문제
05. 임베딩 벡터의 시각화
[1] 필요한 파일 만들기
[2] 임베딩 프로젝터에 tsv파일 업로드하기
06. FastText
[1] FastText의 학습방법
[2] OOV와 오타에 대한 대응
[3] 한국어에서의 FastText
07. GloVe
[1] 잠재 의미 분석(LSA, Latent Semantic Analysis)
[2] 윈도우 기반 동시 등장 행렬(Window based Co-occurrence Matrix)
[3] 동시 등장 확률(Co-occurrence Probability)
[4] GloVe의 손실 함수 설계하기
[5] GloVe 실습