-
[딥러닝구조 및 학습]모델Fundamental Node 2022. 3. 26. 13:42
[딥러닝구조 및 학습]모델
1. 모델구성
2. 모델 레이어/가중치/바이어스 확인
3. 모델 컴파일
4. 모델 학습/평가 및 예측
5. MNIST 딥러닝 모델 예제
6. 모델 저장 및 복원
7. 콜백
========================
[딥러닝구조 및 학습]모델
1. 모델구성
- Sequential API, 함수형 API, Subclassing API
(1) Sequential API
ⓐ 모델이 순차적인 구조로 진행할 때 사용
ⓑ 간단한 방법
- Sequential 객체 생성 후, add()메서드를 이용한 방법
- Sequential 인자로써 리스트형식으로 한번에 추가하는 방법
ⓒ 다중 입력 및 출력이 존재하는 등의 복잡한 모델을 구성할 수 없음
(2) 함수형 API
ⓐ 가장 권장되는 방법
ⓑ 모델을 복잡하고, 유연하게 구성 가능
ⓒ 다중 입출력을 다룰 수 있음.
ⓓ 구성 예시
- 동일한 변수x에 레이어 연결
inputs = Input(shape=(28, 28, 1)) x = Flatten(input_shape=(28, 28, 1))(inputs) x = Dense(200, activation='relu')(x) x = Dense(100, activation='relu')(x) x = Dense(10, activation='softmax')(x) model = Model(inputs=inputs, outputs=x) model.summary()- 입력 레이어 분기/결합
from tensorflow.keras.layers import Concatenate input_layer = Input(shape=(28, 28)) hidden1 = Dense(100, activation='relu')(input_layer) hidden2 = Dense(30, activation='relu')(hidden1) concat = Concatenate()([input_layer, hidden2]) output = Dense(1)(concat) model = Model(inputs=[input_layer], outputs=[output]) model.summary()- 다중입력/단일출력
input_1 = Input(shape=(10, 10), name='input_1') input_2 = Input(shape=(10, 28), name='input_2') hidden1 = Dense(100, activation='relu')(input_2) hidden2 = Dense(10, activation='relu')(hidden1) concat = Concatenate()([input_1, hidden2]) output = Dense(1, activation='sigmoid')(concat) model = Model(inputs=[input_1, input_2], outputs=[output]) model.summary()- 단일입력/다중출력
input_ = Input(shape=(10,10), name='input_') hidden1 = Dense(100, activation='relu')(input_) hidden2 = Dense(10, activation='relu')(hidden1) output = Dense(1, activation='sigmoid', name='main_output')(hidden2) sub_out = Dense(1, name='sum_output')(hidden2) model = Model(inputs=[input_], outputs=[output, sub_out]) model.summary()- 다중입력/다중출력
input_1 = Input(shape=(10, 10), name='input_1') input_2 = Input(shape=(10, 28), name='input_2') hidden1 = Dense(100, activation='relu')(input_2) hidden2 = Dense(10, activation='relu')(hidden1) concat = Concatenate()([input_1, hidden2]) output = Dense(1, activation='sigmoid', name='main_output')(concat) sub_out = Dense(1, name='sum_output')(hidden2) model = Model(inputs=[input_1, input_2], outputs=[output, sub_out]) model.summary()(3) Subclassing API
ⓐ 커스터마이징에 최적화된 방법
ⓑ Model 클래스를 상속받아 Model이 포함하는 기능을 사용할 수 있음
- fit(), evaluate(), predict()
- save(), load()
ⓒ 주로 call() 메소드 안에서 원하는 계산 가능
- for, if, 저수준 연산 등
ⓓ 권장되는 방법은 아니지만 어떤 모델의 구현 코드를 참고할 때, 해석할 수 있어야 함.
class MyModel(Model): def __init__(self, units=30, activation='relu', **kwargs): super(MyModel, self).__init__(**kwargs) self.dense_layer1 = Dense(300, activation=activation) self.dense_layer2 = Dense(100, activation=activation) self.dense_layer3 = Dense(units, activation=activation) self.output_layer = Dense(10, activation='softmax') def call(self, inputs): x = self.dense_layer1(inputs) x = self.dense_layer2(x) x = self.dense_layer3(x) x = self.output_layer(x) return x2. 모델 층(layer)/가중치(wieght)/편향(bias) 확인
- 모델 확인 summary()메소드
- 층 확인 : layers 속성, name속성
- 층 추출 : 인덱스 이용, get_layer()메소드 이용
- 가중치/편향 확인 : get_weights()메소드 이용
3. 모델 컴파일
- 모델을 구성한 후, 사용할 손실함수(loss), 최적화함수(optimizer), 성과지표(metrics)를 지정
model.compile(loss='sparse_categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])(1) 손실함수(Loss Function)
ⓐ 학습이 진행되면서 해당과정이 얼마나 잘 되고 있는지 나타내는 지표
ⓑ 모델이 훈련되는 동안 최소화될 값으로 주어진 문제에 대한 성공 지표
ⓒ 손실함수에 따른 결과를 통해 학습 파라미터를 조정
ⓓ 최적화 이론에서 최소화 하고자 하는 함수
ⓔ 미분 가능한 함수 사용
ⓕ Keras에서 주요 손실함수 제공
- sparse_categorical_crossentropy : 클래스가 배타적 방식으로 구분, 즉(0, 1, 2,..)같은 방식으로 구분되어 있을 때 사용
- categorical_crossentropy : 클래스가 원-핫 인코딩 방식으로 되어 있을 때 사용
- binary_crossentropy : 이진 분류를 수행할 때 사용
- Keras에서 사용되는 손실함수 종류 : https://keras.io/ko/losses/#_2
(2) 최적화함수(optimizer)
1) 개요
ⓐ 손실함수를 기반으로 모델이 어떻게 업데이트되어야 하는지 결정(특정 종류의 확률적 경사하강법 구현)
ⓑ keras에서 여러 최적화함수(optimizer)를 제공
- SGD() : 기본적인 확률적 경사하강법
- Adam() : 자주 사용되는 옵티마이저
- Keras에서 사용되는 옵티마이저 종류 https://keras.io/ko/optimizers/
- 보통 최적화함수의 튜닝을 위해 따로 객체를 생성하여 컴파일
2) 경사하강법(Gradient Decent)
ⓐ 미분과 기울기
ⓑ 변화가 있는 지점에서는 미분값이 존재하고, 변화가 없는 지점은 미분값이 0
ⓒ 미분값이 클수록 변화량이 크다는 의미
ⓓ 경사하강법의 과정
- 경사하강법은 한 스텝마다의 미분값에 따라 이동하는 방향을 결정
- f(x)의 값이 변하지 않을 때까지 반복
3) 학습률(Learning Rate)
- 적절한 학습률을 지정해야 최저점에 잘 도달할 수 있음
- 학습률이 너무 크면 발산하고, 너무 작으면 학습이 오래 걸리거나 최저점에 도달하지 못함.
4) 볼록함수(Convex function)와 비볼록함수(Non-convex function)
5) 안장점(saddle point)
- 기울기가 0이지만 극값이 되지 않음
- 경사하강법은 안장점에서 벗어나지 못함.
(3) 성과지표(metrics)
ⓐ 모니터링할 지표
ⓑ 회귀문제에서는 mae, 분류문제에서는 accuracy(줄여서 acc) 사용
ⓒ Keras에서 제공되는 지표 종류 https://keras.io/ko/metrics/
4. 모델 학습/평가 및 예측
(1) 학습/평가/예측
1) fit()
- x : 학습 데이터
- y : 학습 데이터 정답 레이블
- epochs : 학습 회수
- batch_size : 단일 배치에 있는 학습 데이터의 크기
- validation_data : 검증을 위한 데이터
2) evaluate()
- 테스트 데이터를 이용한 평가
3) predict()
- 임의의 데이터를 사용해 예측
(2) 오차역전파(Backpropagation)
1) 오차역전파 알고리즘
- 학습 데이터로 정방향(forward) 연산을 통해 손실함수 값(loss)을 구함
- 각 층(layer)별로 역전파학습을 위해 중간값을 저장
- 손실함수를 학습 파라미터(가중치, 편향)로 미분하여 마지막 층(layer)로부터 뒤로(backward) 하나씩 연쇄 법칙을 이용하여 미분
- 각 층(layer)를 통과할 때마다 저장된 값을 이용
- 오류(error)를 전달하면서 학습 파라미터를 조금씩 갱신
2) 오차역전파 학습의 특징
- 손실함수를 통한 평가를 한 번만 하고, 연쇄법칙을 이용한 미분을 활용하기 때문에 학습 소요시간이 매우 단축
- 미분을 위한 중간값을 모두 저장하기 때문에 메모리를 많이 사용
3) 신경망 학스에 있어서 미분가능의 중요성
- 경사하강법(gradient descent)에서 손실함수(cost function)의 최소값, 즉 최적값을 찾기 위한 방법으로 미분을 활용
- 미분을 통해 손실함수의 학습 매개변수(trainable parameter)를 갱신하여 모델의 가중치의 최적값을 찾는 과정
4) 합성함수의 미분 : 연쇄법칙
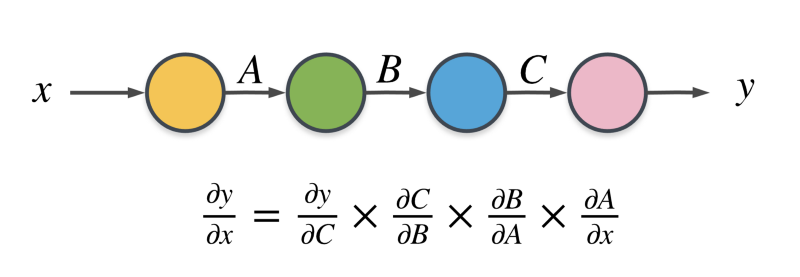
- 여러 개를 연속으로 사용 가능
- 각각에 대한 편미분 적용 가능
5) 오차역전파의 직관적 이해
- 학습을 진행하면서, 즉 손실함수의 최소값을 찾아가는 과정에서 가중치 또는 편향의 변화에 따라 얼마나 영향을 받는지 알 수 있음
5. MNIST 딥러닝 모델 예제
(1) 데이터셋 개요
(2) 모듈 임포트
(3) 데이터 로드, 시각화 및 전처리
(4) 모델 구성
(5) 모델 컴파일 및 학습
(6) 모델 평가 및 예측
6. 모델 저장 및 복원
1) 메서드 : save(), load_model()
2) Sequential API, 함수형 API에서는 모델의 저장 및 로드가 가능하지만, subclassing API방식으로는 할 수 없음
3) subclassing API방식은 save_weights()와 load_weights()를 이용해 모델의 파라미터만 저장 및 로드
4) Json 형식
- 저장 : model.to_json()
- 복원 : model_from_json(file_path)
5) YAML로 직렬화
- 저장 : model.yaml()
- 복원 : model_from_yaml(file_path)
7. 콜백
(0) 개요
- fit()함수의 callbacks 매개변수를 사용하여 케라스가 훈련의 시작이나 끝에 호출할 객체 리스트를 지정할 수 있음.
- 여러 개 사용 가능
(1) Modelcheckpoint
- tf.keras.callbacks.ModelCheckpoint
- 정기적으로 모델의 체크포인트를 저장하고, 문제가 발생할 때 복구하는 데 사용
- 최상의 모델만을 저장 : save_best_only=True
(2) EarlyStopping
- tf.keras.callbacks.EarlyStopping
- 검증 성능이 한동안 개선되지 않을 경우 학습을 중단할 때 사용
- 일정한 patience 동안 검증 세트에 대한 점수가 오르지 않으면 학습을 멈춤
- 모델이 향상되지 않으면 학습이 자동으로 중지되므로, epochs 숫자를 크게 해도 무방
- 학습이 끝난 후의 최상의 가중치를 복원하기 때문에 모델을 따로 복원할 필요 없음.
(3) LearningRateScheduler
- tf.keras.callbacks.LearningRateScheduler
- 최적화를 하는 동안 학습률(learning rate)을 동적으로 변경할 때 사용
(4) TensorBoard
- tf.keras.callbacks.TensorBoard
- 모델의 경과를 모니터링 할 때 사용
- 텐서보드를 사용하기 위해 logs 폴더를 만들고, 학습이 진행되는 동안 로그 파일을 생성
log_dir = './logs' tensor_board_cb = [TensorBoard(log_dir=log_dir, histogram_freq=1, write_graph=True, write_images=True)] model.fit(x_train, y_train, batch_size=32, validation_data=(x_val, y_val), epochs=30, callbacks=tensor_board_cb)- 텐서보드 로드
%load_ext tensorboard%tensorboard --logdir {log_dir}'Fundamental Node' 카테고리의 다른 글
[파이썬]05. 제어문 (0) 2022.03.28 [파이썬]04. 리스트, 튜플, 세트, 딕셔너리 (0) 2022.03.28 [딥러닝]딥러닝 구조 및 학습-레이어 (0) 2022.03.25 [딥러닝]드롭아웃(Dropout) (0) 2022.03.24 [딥러닝]가중치 초기화 (0) 2022.03.24